


【新智元导读】AIoT的时代即将来临,移动端智能应用呈爆发式增长,但是大型神经网络在移动端的性能制约了AI在移动端的推广。最近,依图团队发表在ECCV的一篇论文,提出了新一代移动端神经网络架构MobileNeXt,大大优于谷歌的MobileNet、何恺明团队提出的ResNet等使用倒残差结构的模型,为移动端算力带来了新的突破。
《三体》中罗辑沉睡了两个世纪后,k8凯发天生赢家一触即发在位于地下一千多米的城市中醒来;《流浪地球》中,行星推进器下500米的地下城。

未来,随着人类栖息空间的不断延展和拓宽,现存的城市管理体系注定会失效,必将需要一个高度复杂的智能系统来维护,而打造智慧城市,要完成交通、供水、供电、供气、通讯、环保等等基础设施的数字化建设,但是很少有城市关注到。
而上海的「一网统管」系统做到了,小到每一个路灯、井盖、消防栓,大到26000多公里的地下管网,都被连接了起来,让城市的精细化管理成为可能。
这个「一网统管」得益于依图自主研发的人工智能芯片,人工智能算力在城市管理中规模化落地的可能性被大大释放,为此还得到了央视《新闻联播》“十三五”成就巡礼专题的点赞。

依图研发团队近期在 ECCV 2020 发表了新论文,通过分析当前主流移动端网络的倒残差模块的优势与劣势,提出了一种改良版本MobileNeXt,大大提升了移动端神经网络的性能。

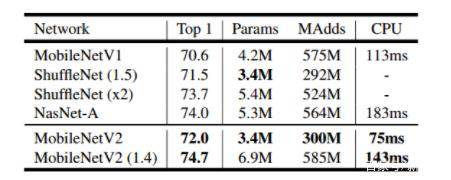
在不使用SE等性能提升模块的条件下,相比于主流的MobileNetV2,MobileNeXt在相同计算量下可达到1.7%的分类精度提升。
此外,新提出的沙漏模块可用于改良神经网络自动化搜索的搜索空间,在使用相同搜索算法的情况下,加入沙漏模块的搜索空间可以在CIFAR10的数据集上取得更高效的模型架构,大大优于谷歌的MobileNet、何恺明团队提出的ResNet等使用倒残差结构的模型。
谷歌在2017年提出了专门为移动端优化的轻量级CNN网络,该研究最大的亮点是提出了深度可分离卷积(depthwise separable convolution)。
传统卷积分两步,每个卷积核与每个特征图按位相乘,然后再相加,此时,计算量为,其中为特征图尺寸,为卷积核尺寸,M为输入通道数,N为输出通道数。
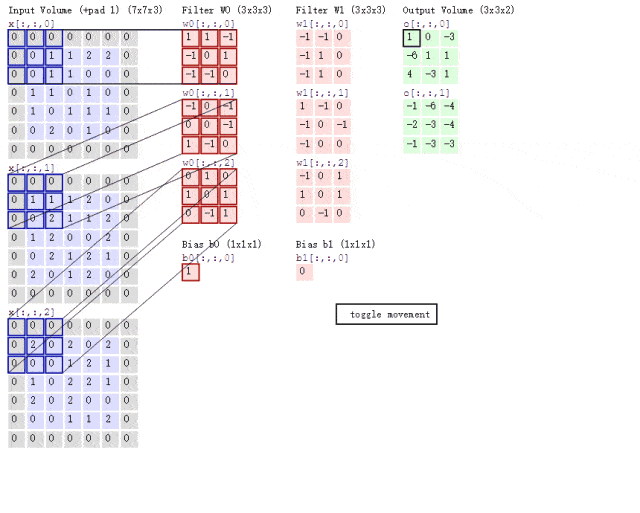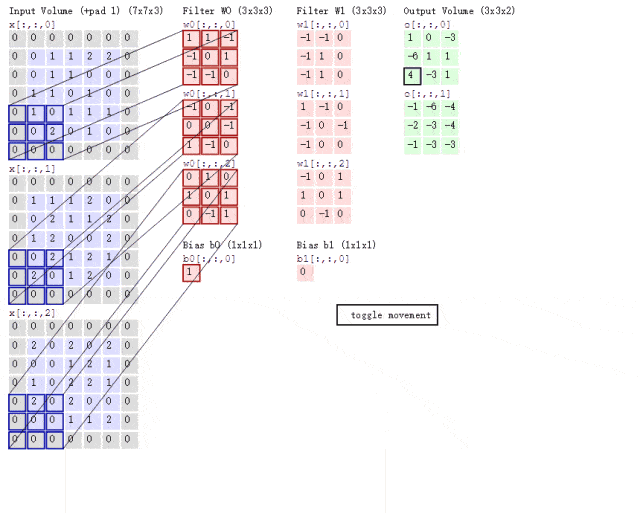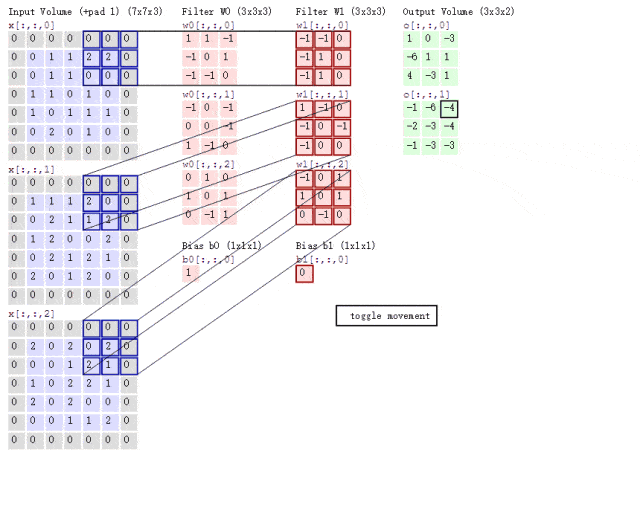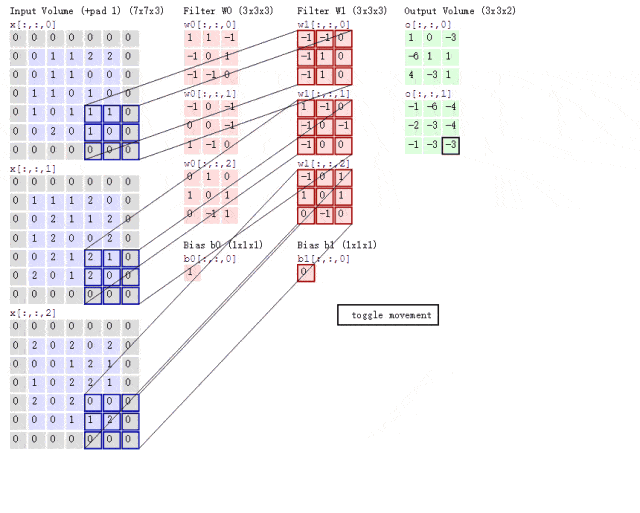
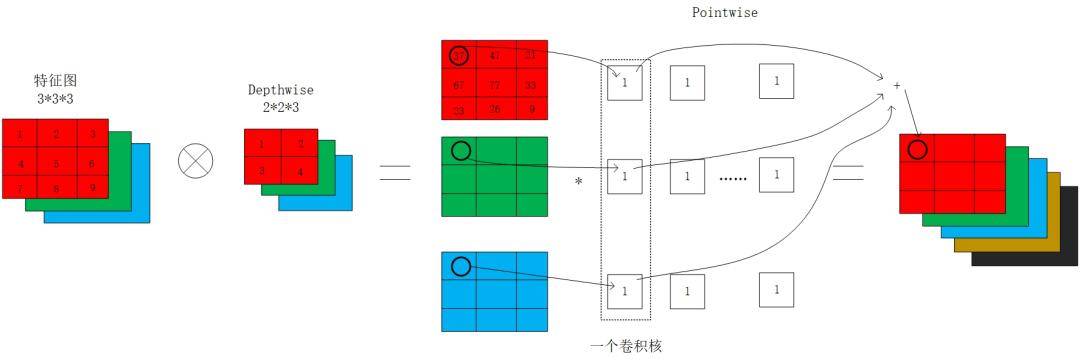
而谷歌提出的深度可分离卷积,将普通卷积拆分成了一个深度卷积depthwise和一个逐点卷积pointwise。
首先按通道进行按位相乘,通道数没有改变;然后将第一步的结果,使用1*1的卷积核进行传统的卷积,此时通道数可以进行改变。使用了深度可分离卷积,其计算量变为+11。
MobileNet V1的速度虽然提高了,但是低维信息映射到高维的维度较低,经过ReLU后再映射回低维时损失比较大,所以谷歌在V1的基础上,又引入了倒残差(Inverted Residuals)和线性瓶颈(Linear Bottlenecks)两个模块,使得MobileNetV2降低时延的同时精度也有所提升。
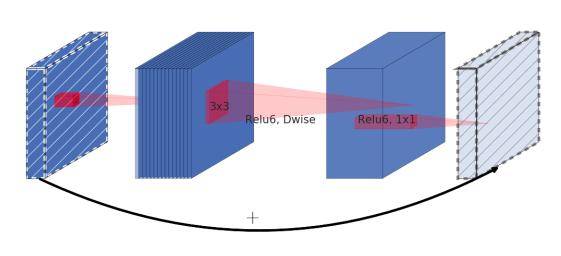
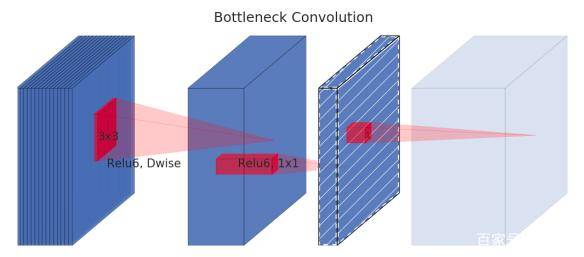
同时,瓶颈结构的连接方式可以有效降低点操作的数量、减少所需要的内存访问,进而进一步减小硬件上的读取延时,提升硬件执行效率。
然而,MobileNetV2集中于瓶颈结构的网络连接方式可能会造成优化过程中的梯度回传抖动,进而影响模型收敛趋势,导致模型性能降低。
现有研究表明:(1) 更宽的网络可以缓解梯度混淆问题并有助于提升模型性能;(2)逆残差模块中的短连接可能会影响梯度回传。
为了解决MobileNetV2中瓶颈结构导致的优化问题,依图团队重新思考了由ResNet提出的传统瓶颈结构的链接方式,这种连接方式把梯度主要集中在较高维度的网络层,可以减少梯度抖动、加速网络收敛。
于是便有了一种新的网络设计模块--沙漏型瓶颈结构,既能保留高维度网络加速收敛和训练的优势,又能利用深度卷积带来的计算开销收益,减少高维特征图的内存访问需求,提高硬件执行效率。
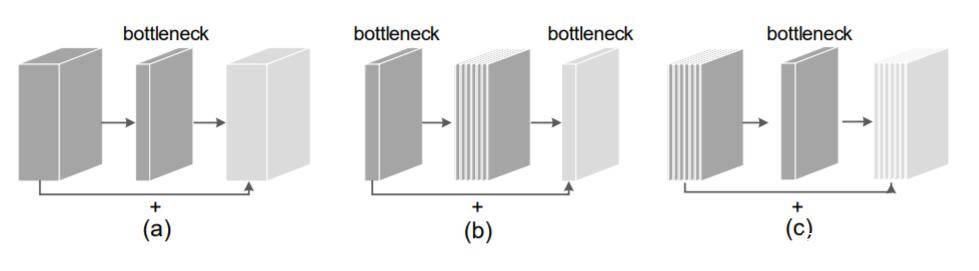
依图团队把跳跃链接放置在高维度神经网络层,并使用深度卷积来降低计算开销,然后使用两连续层1x1卷积来进一步降低计算开销的效果。
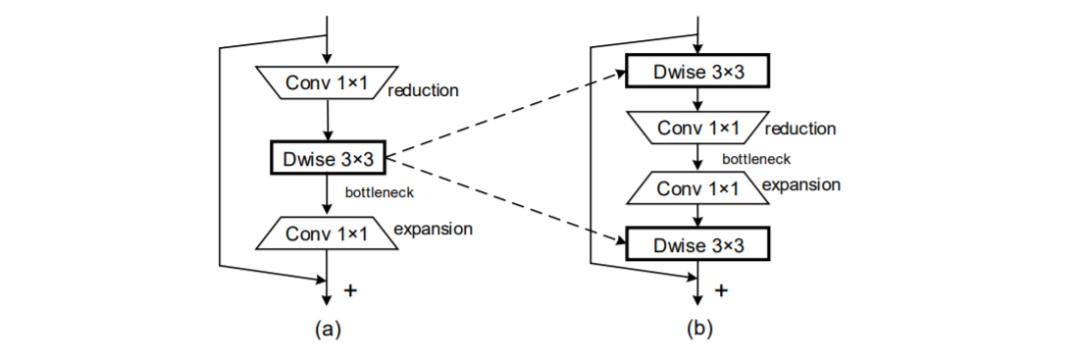
可以看到,Sandglass Block可以保证更多的信息从bottom层传递给top层,进而有助于梯度回传;执行了两次深度卷积以编码更多的空间信息。
依图团队并未在瓶颈层间构建短连接,而是在更高维特征之间构建短连接(见图三b)。更宽的短连接有助于更多信息从输入F传递给输出G,从而有更多的梯度回传。
与此同时,由于高维度的跳跃链接会导致更多的点加操作、需求更多的内存读取访问,直接连接高维度跳跃链接会降低硬件执行效率。
一种新颖的残差跳跃连接可以解决这一问题:即只使用一部分信息通道进行跳跃链接。这一操作可直接减少点加操作和特征图大小,进而直接提升硬件执行效率。
我们知道,1x1卷积有助于编码通道间的信息,但难以获取空间信息,而深度卷积可以。因此依图团队沿着倒残差模块的思路引入了深度卷积来编码空间信息。
倒残差模块的深度卷积在两个1x1卷积之间,而1x1卷积会降低空域信息编码,因此依图团队将深度卷积置于两个1x1卷积之外(见图三b中的两个3x3深度卷积),这样就能确保深度卷积在高维空间得到处理并获得更丰富的特征表达。
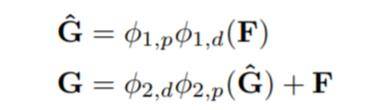
线性瓶颈层有助于避免特征出现零化现象导致的信息损失,因此在降维的1x1卷积后不再添加激活函数。同时最后一个深度卷积后也不添加激活函数,激活函数只添加在第一个深度卷积与最后一个1x1卷积之后。

依图一直是稳扎稳打型的选手k8凯发,做研究也很务实、不追求多和杂,梯度抖动就解决抖动的问题,损失大就想办法降低损失,追求的是实用和落地,而不是去刷各种比赛的榜单。
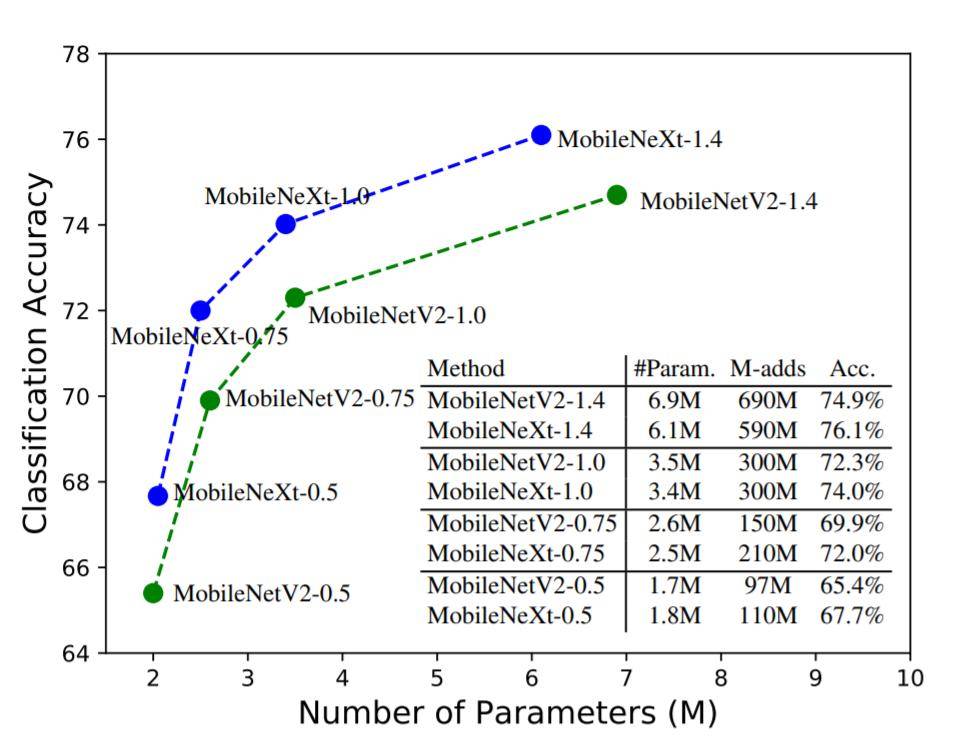
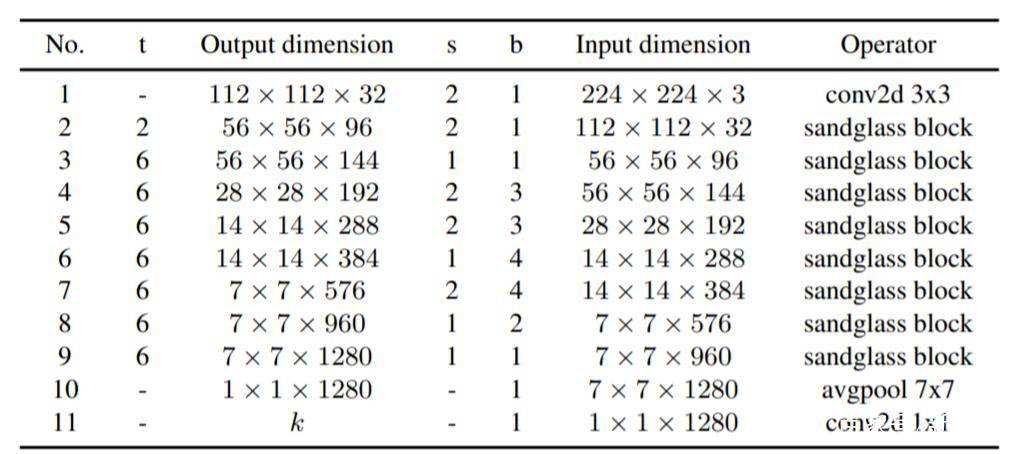
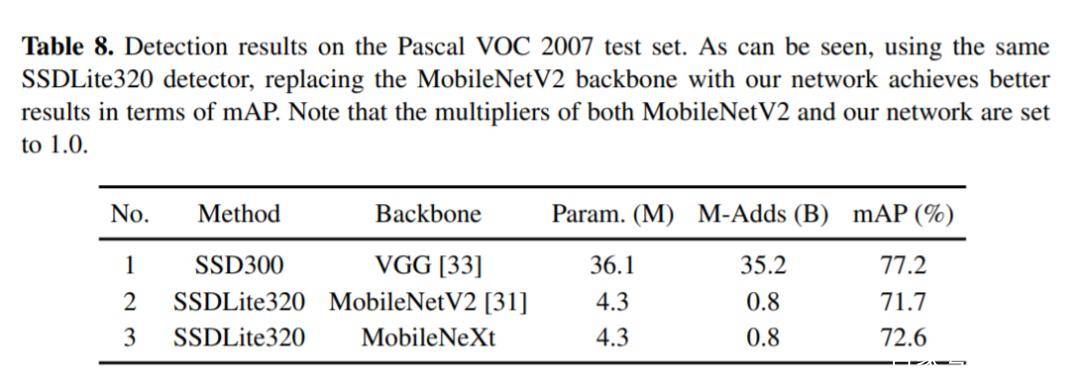
既然是基于移动端的网络,依图团队在Google Pixel手机上进行了测试,看MobileNeXt跟MobileNet V2相比,性能有多少提升。
在PyTorch环境下,可以看到MobileNeXt在不同大小的模型下,精度均优于MobileNetV2,而且模型越小,这种优势越明显。
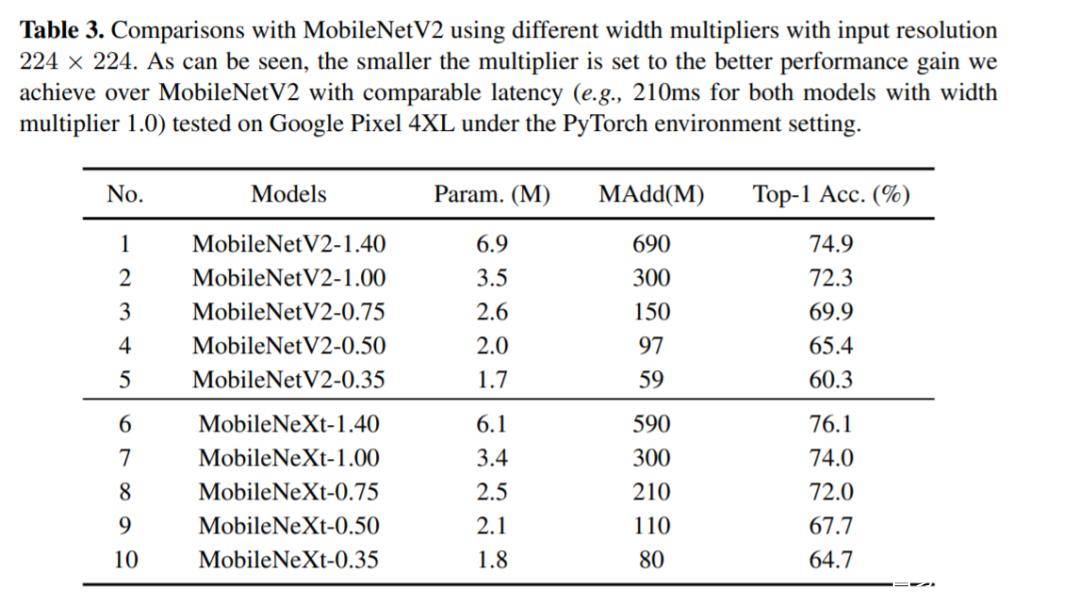
当与后训练量化方法结合时,MobileNeXt也有很大优势。(后训练量化可以简单看做模型压缩)
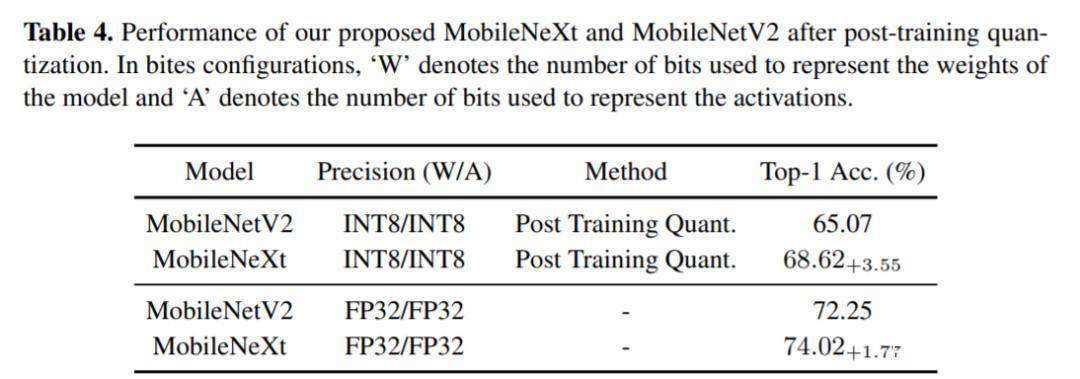
硬件执行效率方面,仅使用部分新系统进行跳跃链接可有效提高硬件执行效率。值得注意的是,在进行残差信息通道实验的时候,没有使用任何额外的监督信息(比如知识蒸馏)。k8凯发天生赢家一触即发
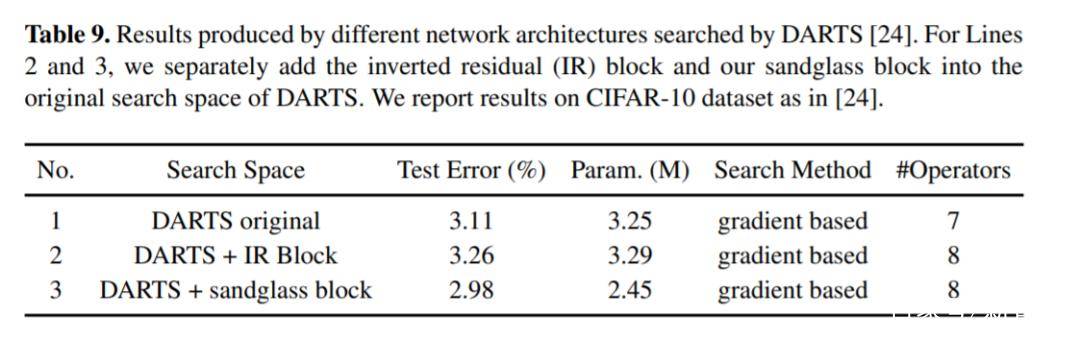
神经网络搜索方面,为验证信息处沙漏模型的高效性,依图团队使用新提出的沙漏模型对神经网络搜索的搜索空间进行了扩充。在使用相同搜索算法的情况下,基于扩充空间的搜索结果可以得到0.13% 的精度提升,同时减少25% 的参数量。
透过现象看本质,是研发团队成功设计沙漏型瓶颈模块及MobileNeXt的根本所在,可以看到,基础领域的进展最终靠的还是自身扎实的基本功。
从这个层面讲,依图早已不再是传统意义上的CV公司,而是凭借基础算法的优势和芯片的加持,逐渐成长为新一代的AI算力厂商。
未来,不光移动端,云端和边缘端的厂商也将从依图的软硬件协同算法创新中获益,节约自主开发的算力成本,更好地驱动整体业务。
从看、听再到本质的理解,机器的智能在不断进化中逐渐迈向更高的维度,我们看到,依图正在努力将智能化的理论不断付诸实践,成为AI落地的引路人。
